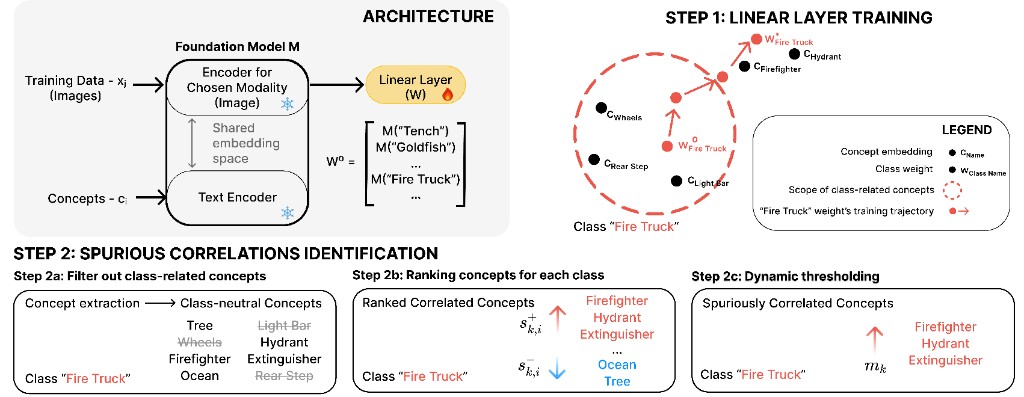
We pursue a simple goal: to understand not just whether models work, but why they work, when they fail, and what they are truly relying on under the hood. Our research focuses on robust generalization under distribution shift, the emergence of spurious correlations and shortcut strategies, and the internal mechanisms that drive these behaviors. We develop methods that go beyond merely cataloging failures after the fact by revealing hidden biases in learned representations, tracing shortcut learning through embeddings and weight space, and testing whether models can transfer abstract knowledge beyond the settings in which it was first acquired.

Academic
Generalization & Interpretability
Pathways of Visual Information Flow in Vision-Language Models
Links: arXiv
Abstract We study how visual information is routed in vision-language models (VLMs). Using causal patching on controlled synthetic and …