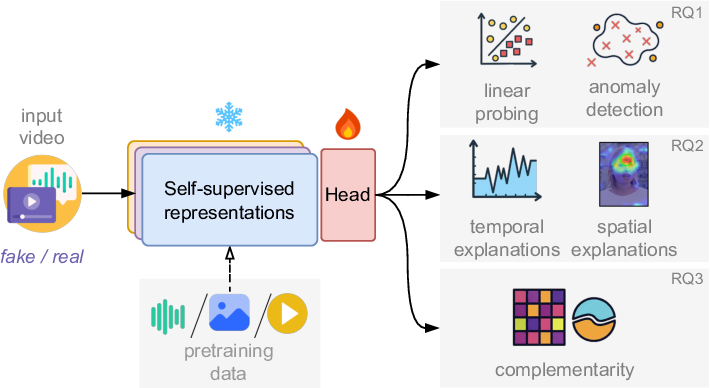
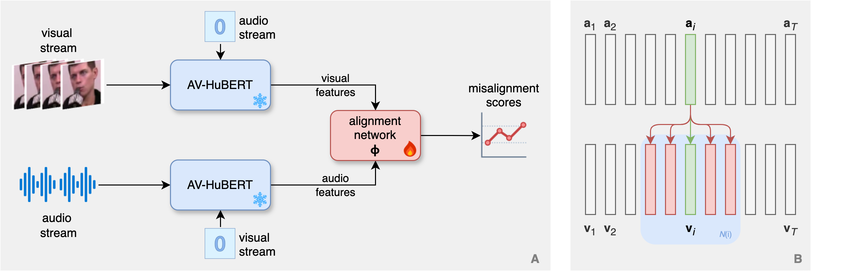
We focus on advancing deepfake detection across video and audio modalities. Our research is guided by three goals: (i) Generalization: develop methods that transfer across diverse datasets and forgery techniques. (ii) Transparency: understand how detection models make decisions and ensure datasets are reliable (free of spurious shortcuts). (iii) Deployability: build systems that adapt and remain robust on unconstrained “in-the-wild” content.

Academic
Deepfake Detection
Anchoring the Unknown: Open-Set Model Attribution via Proxy-Anchor Learning
Links: arXiv
Abstract The proliferation of text-to-speech (TTS) systems capable of generating realistic synthetic speech poses growing challenges for …