🕹️ Pretrained Atari Agents
Releasing trained models in computer vision and natural language processing has been a major source of progress for the research in these fields and a significant catalyst for the adaption of deep learning models in the industry. By comparison, RL agents pretrained on otherwise resource and time intensive benchmarks such as Arcade Learning Environment are rather hard to come by.
Today, our research group within Bitdefender is making available over 2️⃣5️⃣,0️⃣0️⃣0️⃣ agents trained on 60 games in the Arcade Learning Environment. We hope the diversity and the quality of these trained models will help spur new research in multi-task and imitation learning and contribute to the state of reproducibility in deep reinforcement learning.
The performance of these agents closely matches figures published in the literature and have been used as strong baselines in published and unpublished work. The agents included in this release are Munchausen-DQN and Adam-optimised DQN that compare favourably with more complex agents as well as a C51 agent whose performance matches or exceeds the results reported in the paper that introduced it. We provide three independent training runs for each agent-game combination with the exception of on agent for which we only provide two seeds. We plan to continue releasing new models.
Another feature of this release is the extreme ease of experimenting with the agents. No RL frameworks are required, the dependency list is kept to a minimum, the code is self-contained and takes just two files, making it a breeze to quickly load a checkpoint, visualize the gameplay at high resolution and record it. The simplicity of the code also makes it possible to easily modify the scripts for your own purposes. Converting these models for use in other deep learning frameworks should also be possible.
We encourage you coming with suggestions of how to make this repository of trained models better and more useful. Relevant links:

How we trained the agents
A major reason for deciding to publish these models is the sheer amount of time required to run DQN-style algorithms on the Atari benchmark. This is especially difficult for small labs.
For this release we used "only" 20 to 40 GPUs (a wide assortment ranging from GTX Titan to newer RTX consumer models) from our cluster at Bitdefender, for a combined running time of about two months for learning all the agents. Considering a full run on ALE requires 3 seeds 60 games and a single DQN-style agent takes a bit over one week this might seem a bit surprising. What made this possible is that we figured out early that you could launch three to four DQN processes on a single GPU provided the replay buffer is stored in the system RAM. The penalty incurred in terms of wall clock times is easily offset by parallelization in this case.
This is one of the reason our agents have been trained using our own PyTorch implementations and while the code used is not readily available we consider publishing it if there is demand for it.
A word on training and evaluation protocols
There are two common training and evaluation protocols encountered in the literature. We named them classic and modern across this project:
classic: it originates from (Mnih, 2015)2 Nature paper and it mostly appears in DeepMind papers.modern: it originates from (Machado, 2017)1 and a variation of it was adopted by Dopamine6. Since then it started to show up more often in recent papers.
The main two differences between the two are the way stochasticity is induced in the environment and how the loss of a life is treated.
The current crop of agents is summarized below.
| Algorithm | Protocol | Games | Seeds | Observations |
|---|---|---|---|---|
| DQN | modern | 60 | 3 | DQN agent using the settings from dopamine. It's optimised with Adam and uses MSE instead of Huber loss. A surprisingly strong agent on this protocol. |
| M-DQN | modern | 60 | 3 | DQN above but using the Munchausen trick7. Even stronger performance. |
| C51 | classic | 28/57 | 3 | Closely follows the original paper3. |
| DQN Adam | classic | 28/57 | 2 | A DQN agent trained according to the Rainbow paper4. The exact settings and plots can be found in our paper5. |
Right off-the bat you can notice that on the classic protocol there are only 28 games out of the usual 57. We trained the two agents on this protocol over one year ago using the now deprecated atari-py project which officially provided the ALE Python bindings in OpenAI's Gym. Unfortunately the package came with a large number of ROMs that are not supported by the current, official, ale-py library. The agents trained on the modern protocol (as well as the code we provide for visualising agents) all use the new ale-py. Therefore we decided against providing support for the older library event if it meant dropping half of the trained models. A great resource for reading about this issue is Jesse's Farebrother ALE v0.7 release notes. Importantly, we found out about the issue while checking the performance of the trained models on the new ale-py back-end and we provide plots showing the remaining 28 agents perform as expected (C51_classic, DQN_classic).
{kind=link}
{kind=link}
How many checkpoints?
An agent trained on 200M frames usually produces 200 checkpoints times the number of training seeds. In order not to make the download size overly large we only include 51 checkpoints per training run. These are sampled geometrically, with denser checkpoints towards the end of the training. This results in the last 20 checkpoints of the full 200 (last 10% of the training run) and then sparser checkpoints towards the beginning of the run, with only 10 out of 51 from the first half. It looks a bit like this:

Note it's not mandatory the best performing checkpoint is included since on some combinations of algorithms and agents the peak performance occurs earlier in training. However this sampling should characterize fairly well the performance of an agent most of the time.
❗✋ If requested, we can provide the full list of checkpoints for a given agent.
Agents have been trained using PyTorch and the models are stored as compressed state_dict pickle files. Since the networks used on ALE are fairly simple these could easily be converted for use in other deep learning frameworks.
Just how well trained are these agents?
Our PyTorch implementation of DQN trained using Adam on the modern protocol compares favourable to the exact same agent trained using Dopamine. The plots below have been generated using the tools provided by rliable.
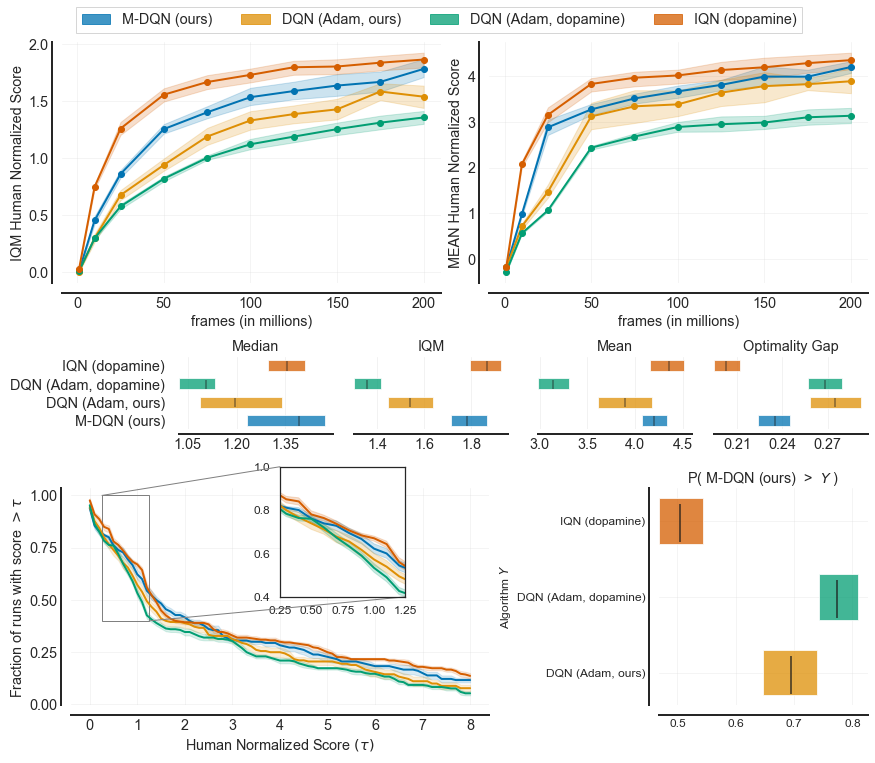
A detailed discussion about the performance of DQN + Adam and C51 trained on the classic protocol can be found in our paper5, where we used these checkpoints as baselines.
References
- Mnih, et al. 2015, _Human-level control through deep reinforcement learning↩
- Machado, et al. 2017, Revisiting the Arcade Learning Environment...↩
- Castro, et al. 2018, Dopamine: A Research Framework for Deep RL↩
- Hessel, et al. 2017, Combining Improvements in Deep RL↩
- Gogianu, et al. 2021, Spectral Normalisation...↩
- Bellemare, et al. 2017, A distributional perspective...↩
- Vieillard, et al. 2020, Munchausen Reinforcement Learning↩