Large Language Models for Malware Analysis
Large Language Models (LLMs) took the world by storm in 2023, revolutionizing the way people search and generate text content. LLMs for code have also made inroads in helping people understand code or write code based on requests in natural language. For instance, translating requests to SQL queries has rapidly advanced since the advent of GPT4.
Most popular code LLMs focus on generating or understanding high-level programming languages such as Python, C++, Java etc. [1],[2],[3],[4]. However code LLMs tailored to malware analysis should be adapted to better understand assembly code as well. Recent works also explore this avenue [5],[6],[7].
To this end we start from existing general-purpose LLMs such as MPT7B, which has been trained on both English text and code. We adapt them to x86-64 assembly data, by finetuning them using the Causal Language Modeling task and the LoRA method. We then inspect these models to evaluate the quality of their embeddings and their generation capabilities. We call these models asmLLMs.
asmLLMs for feature extraction
Features learned by pretrained models are crucial for downstream tasks such as anomaly detection, search or classification. Most LLMs (either general purpose or code-based) have little assembly data in their pretraining corpus relative to the entire corpus. Finetuning LLMs on more assembly data should then result in better features. To test this, we developed several downstream classification tasks, where the input is assembly code. Classifiers trained on features from the asmLLM should then outperform classifiers trained on features from base LLMs.
To build examples for our tasks, we took C++ solutions from the code contest dataset CodeNet 1000 and converted them to assembly. The three classification tasks are:
- Complexity prediction, where the input is the assembly corresponding to a C++ function, and the label is the cyclomatic complexity of that function (13 classes)
- Problem identification, where the input is the assembly corresponding to a C++ submission to a code contest, and the label is the ID of the contest problem (20 classes)
- Accuracy prediction, where the input is the assembly corresponding to a C++ submission to a code contest, and the label is the score achieved by the submission on the benchmark. Instead of predicting the score, the model predicts a class from a set of 5 classes, where each class corresponds to different bins of performance: [0-20) score, [20-40) score, ..., [80-100].
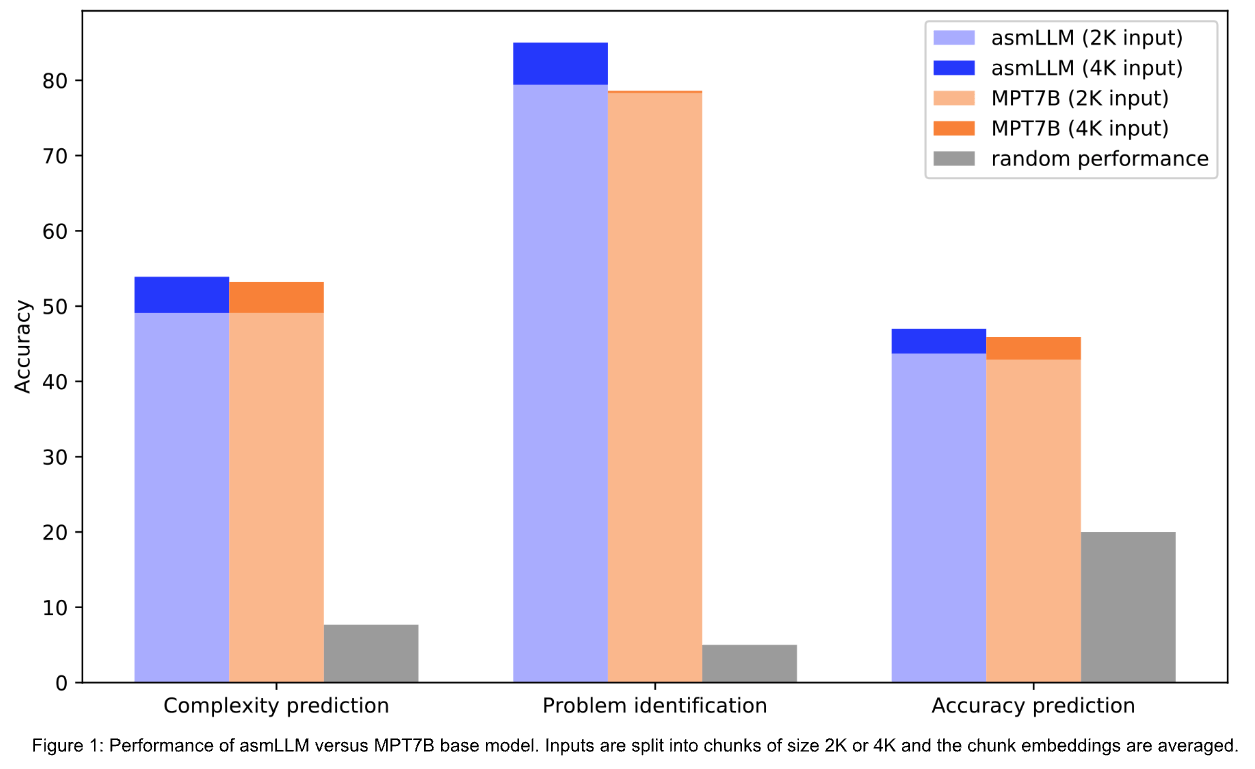
The asmLLM in Figure 1 is an MPT7B-base finetuned on assembly data using sequences of length 2K. To embed an input, it is first split into chunks of length 2K or 4K tokens. The input embedding is then computed as the average over these chunk embeddings. Results show that classifiers benefit from features from asmLLMs, especially when using larger contexts (4K tokens vs 2K tokens).
asmLLMs for generative tasks
Code repair
While asmLLMs can be used as feature extractors, we are also interested in generative settings such as code-to-code or code-to-text. A typical code-to-code task is code repair, where given a faulty piece of code, the correct version of the code is produced. To test this on assembly, we generate a synthetic dataset where we alter a percentage of the assembly tokens, by modifying instructions (e.g. mov -> lea), registers (rax -> rsp) or offsets. We then perform instruction tuning on the asmLLM using (altered assembly, correct assembly) pairs and a 4K token context.

We notice in Figure 2 that the instruction tuned asmLLM model can correctly predict altered instructions (movzx -> mov) or registers (ch->rax).
Code summarization
To inspect the code of executable files, malware analysts use a wide array of tools, including powerful decompilers and disassemblers. While top performing LLMs such as GPT-4 are good at explaining high-level languages such as Python or C++, they are less likely to get the big picture of assembly code and instead describe it line by line usually. We are thus interested in the code summarization task, where explaining large chunks of assembly code can help analysts delve into binaries more efficiently.
For this task, we generate a synthetic instruction tuning dataset called OSS-ASM, which consists of (assembly code, explanation) pairs. We first use the OSS-instruct[8] method to produce (C++ code, explanation) pairs by seeding LLMs with assembly snippets from various technical resources. We then convert the C++ code to x86-64 assembly.
| Model | Rouge-L | BLEU |
|---|---|---|
| GPT-3.5 turbo | 23.22 | 2.85 |
| GPT-4 | 26.56 | 4.03 |
| MPT7B-base + instruction tuning OSS-ASM | 33.22 | 11.89 |
| MPT7B-instruct + instruction tuning OSS-ASM | 33.92 | 12.29 |
| asmLLM + instruction tuning OSS-ASM | 35.72 | 13.65 |
The asmLLM model in the table above is a MPT7B-base, finetuned on a subset of 500M tokens of x86-64 assembly, with LoRA rank r=64 and context length L=4096 tokens. GPT-3.5 and GPT-4 are tested in a zero-shot setup, while the other three models are instruction tuned on the OSS-ASM dataset. Results show that adapting base LLMs on assembly data improves the performance on downstream generative tasks such as code summarization.
Along with results in Figure 1, this highlights the importance of pretraining LLMs on domain-specific data, particularly when dealing with languages that are less represented in large training sets, such as assembly.
asmLLMs can become an essential item in a malware analysis toolkit, accelerating the inspection of binaries and improving the threat response time. Future work involves learning across different computer architectures, increasing the diversity of the instruction tuning data and tackling obfuscated code.
References
- Code Llama: Open Foundation Models for Code, https://arxiv.org/abs/2308.12950
- StarCoder: may the source be with you!, https://arxiv.org/abs/2305.06161
- WizardCoder: Empowering Code Large Language Models with Evol-Instruct, https://arxiv.org/abs/2306.08568
- OctoPack: Instruction Tuning Code Large Language Models, https://arxiv.org/abs/2308.07124
- Binary Code Summarization: Benchmarking ChatGPT/GPT-4 and Other Large Language Models, https://arxiv.org/abs/2312.09601
- CP-BCS: Binary Code Summarization Guided by Control Flow Graph and Pseudo Code, https://arxiv.org/abs/2310.16853,
- Nova+: Generative Language Models for Binaries, https://arxiv.org/abs/2311.13721
- Magicoder: Source Code Is All You Need, https://arxiv.org/abs/2312.02120
Credits
Photo by Markus Spiske on Unsplash.